Azure Search is a great service that allows developers to add search functionality in their applications. I blogged about [how to index and query data from SQL Server using Azure Search](GHOST_URL/indexing-and-searching-sql-server-data-with-azure-search/" target="_blank) before. Today, I want to talk about a more advanced scenario and one that could be more common than you think.
By default, every Search index is designed to pull data from one source. The source can be a SQL Database, a blob storage or Azure Table Storage. However, there are valid scenarios where you may want to combined data from multiple sources in the same search index. There are a couple of ways to approach this:
- Create an API that performs multiple queries against multiple indexes and then returns the combined dataset
- Use the built-in functionality and push multiple datasources into the same index.
It took a while to work this out because there are some caveats. For example, all datasources need to have the same key. But how do you achieve this? SQL usually has a primary key column (usually with auto increment) whereas blob storage, for example, has no keys by default. To bring multiple datasource together under the same index, we need to identify a common key on both (or all datasources) that will be used to join the records under a single search index.
Making it work
We will start with the schema on the SQL table which will be used as the basis of the combined index. The schema looks like this:
[CustomerID]
[NameStyle]
[Title]
[FirstName]
[MiddleName]
[LastName]
[Suffix]
[CompanyName]
[SalesPerson]
[EmailAddress]
[Phone]
[PasswordHash]
[PasswordSalt]
[rowguid]
[ModifiedDate]
The CustomerID, in this instance, is the primary key. The code that creates the Azure Search Index is below:
private static IList<Field> GetSqlFields()
{
return new List<Field>
{
new Field("CustomerID", DataType.String, AnalyzerName.EnMicrosoft)
{ IsKey = true },
new Field("ModifiedDate", DataType.DateTimeOffset)
{ IsSearchable = false, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("NameStyle",DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("Title", DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("FirstName",DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("MiddleName",DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("LastName",DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("Suffix",DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("CompanyName",DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("SalesPerson",DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("EmailAddress",DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("Phone", DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable= true, IsSortable= true },
new Field("content", DataType.String, AnalyzerName.EnMicrosoft)
{ IsSearchable = true, IsFilterable=false, IsRetrievable = true, IsFacetable=true, IsSortable=true}
};
}
private static Index CreateCombinedIndex(SearchServiceClient searchService)
{
Index index = new Index(
name: "sql-blob-index",
fields: GetSqlFields());
bool exists = searchService.Indexes.ExistsAsync(index.Name).GetAwaiter().GetResult();
if (exists)
{
searchService.Indexes.DeleteAsync(index.Name).Wait();
}
searchService.Indexes.CreateAsync(index).Wait();
return index;
}
The important bit in the above code is the extra field at the end of the code the creates the index field collection. The field in question is content. When working with Search and Blobs, the following properties are exposed, as long as you go for both content and metadata:
- All user metadata properties
- All built-in/system metadata properties:
- metadata_storage_name (Edm.String) - the file name of the blob.
- metadata_storage_path (Edm.String) - the full URI of the blob, including the storage account
- metadata_storage_content_type (Edm.String) - content type as specified by the code you used to upload the blob. For example, application/octet-stream.
- metadata_storage_last_modified (Edm.DateTimeOffset) - last modified timestamp for the blob. Azure Search uses this timestamp to identify changed blobs, to avoid reindexing everything after the initial indexing.
- metadata_storage_size (Edm.Int64) - blob size in bytes.
- metadata_storage_content_md5 - MD5 hash of the blob content, if available.
- content the blob content as crawled and indexed by the Azure search indexer
You should carefully consider which extracted field should map to the key field for your index. The candidates are:
- metadata_storage_name - this might be a convenient candidate, but note that 1) the names might not be unique, as you may have blobs with the same name in different folders, and 2) the name may contain characters that are invalid in document keys, such as dashes. You can deal with invalid characters by using the
base64Encodefield mapping function - metadata_storage_path - using the full path ensures uniqueness, but the path definitely contains / characters that are invalid in a document key. Again, you should encode the keys using the
base64Encodefunction.
However, if we want to combine blob data with data from other datasources, we need to use a common property that makes more sense - the key. The easiest way to achieve this is to use a custom metadata property which needs to be added to the blobs. This usually happens as we write/create the blobs in Azure Storage. It's easy to append metadata properties using either the REST API or the SDK.
For this example, I'll assume that we already have the metadata property attached to our blobs so that we can combine it with our SQL datasource. The content in the index is used to expose the contents of the blob. However, since the content field has been defined it as Searchable any matches against the indexed blob data will also pull data from SQL. That's the beauty of the combined index.
The code to get the Blob data in the same index is attached below. Remember, we need an Indexer and a DataSource in order for Azure Search to be able to work with Blobs
private static Indexer CreateStorageBlobIndexer(SearchServiceClient searchService, Index index, string dataSourceName)
{
Console.WriteLine("Creating Azure Blob indexer...");
var indexer = new Indexer(
name: "azure-blob-indexer",
dataSourceName: dataSourceName,
targetIndexName: index.Name,
fieldMappings : new List<FieldMapping> { new FieldMapping("uniqueblobkey", "CustomerID") },
schedule: new IndexingSchedule(TimeSpan.FromDays(1)));
var exists = searchService.Indexers.ExistsAsync(indexer.Name).GetAwaiter().GetResult();
if (exists)
{
searchService.Indexers.ResetAsync(indexer.Name).Wait();
}
searchService.Indexers.CreateOrUpdateAsync(indexer).Wait();
return indexer;
}
private static DataSource CreateBlobDataSource()
{
DataSource datasource = DataSource.AzureBlobStorage(
name: "azure-blob",
storageConnectionString: AzureBlobConnectionString,
containerName: "search-data");
return datasource;
}
The most important bit in the Indexer code above is the fieldMappings section. This is what we use to map our custom metadata property to the Index key, i.e. CustomerID so that the unified search works across both datasources. We populate the uniqueblobkey metadata property with the CustomerID value at the time of creation.
Next we need to create the indexer and the datasource for the SQL data.
private static DataSource CreateSqlDataSource()
{
DataSource dataSource = DataSource.AzureSql(
name: "azure-sql",
sqlConnectionString: AzureSQLConnectionString,
tableOrViewName: "SalesLT.Customer");
dataSource.DataChangeDetectionPolicy = new SqlIntegratedChangeTrackingPolicy();
return dataSource;
}
private static DataSource CreateBlobDataSource()
{
DataSource datasource = DataSource.AzureBlobStorage(
name: "azure-blob",
storageConnectionString: AzureBlobConnectionString,
containerName: "search-data");
return datasource;
}
private static Indexer CreateSqlIndexer(SearchServiceClient searchService, Index index, string dataSourceName)
{
Console.WriteLine("Creating Azure SQL indexer...");
var indexer = new Indexer(
name: "azure-combined-sql-indexer",
dataSourceName: dataSourceName,
targetIndexName: index.Name,
schedule: new IndexingSchedule(TimeSpan.FromDays(1)));
var exists = searchService.Indexers.ExistsAsync(indexer.Name).GetAwaiter().GetResult();
if (exists)
{
searchService.Indexers.ResetAsync(indexer.Name).Wait();
}
searchService.Indexers.CreateOrUpdateAsync(indexer).Wait();
return indexer;
}
The 2 indexers above take the same Search Index. This is what makes the whole thing work!
Populating the Search Service
I've created a small console application like in the [previous post] to create and populate our Search Index. If you're not using an SDK, you can easily achieve the same functionality using the REST API that the Azure Search exposes. However, as a developer, I find it easier to manage my Azure Service using the .NET SDK. This is what my main() method looks like:
private static string SearchServiceName = "your Azure Search Service name as you defined it in Azure";
private static string SearchServiceAdminApiKey = "you search API key";
private static string AzureSQLConnectionString = "<your SQL Server connection string>";
private static string AzureBlobConnectionString = "<your Blob Storage Connection string>";
static async Task Main(string[] args)
{
var searchService = new SearchServiceClient(
searchServiceName: SearchServiceName,
credentials: new SearchCredentials(SearchServiceAdminApiKey));
Console.WriteLine("========================================");
Console.WriteLine("Creating Combined SQL and Blob combined Index...");
var combinedIndex = CreateCombinedIndex(searchService);
Console.WriteLine("Creating Blob data source...");
var blobDataSource = CreateBlobDataSource();
await searchService.DataSources.CreateOrUpdateAsync(blobDataSource);
Console.WriteLine("Creating SQL data source...");
DataSource sqlDataSource = CreateSqlDataSource();
Console.WriteLine("Creating SQ and Blob data indexers...");
var blobIndexer = CreateStorageBlobIndexer(searchService, combinedIndex, blobDataSource.Name);
var combinedSqlIndexer = CreateCombinedSqlIndexer(searchService, combinedIndex, sqlDataSource.Name);
Console.WriteLine("Running Azure Blob and SQL indexers...");
await searchService.Indexers.RunAsync(blobIndexer.Name);
await searchService.Indexers.RunAsync(combinedSqlIndexer.Name);
Console.WriteLine("Press any key to continue...");
Console.ReadKey();
}
Running this short program, it will go an populate our Azure Search Index. The output should look like this:
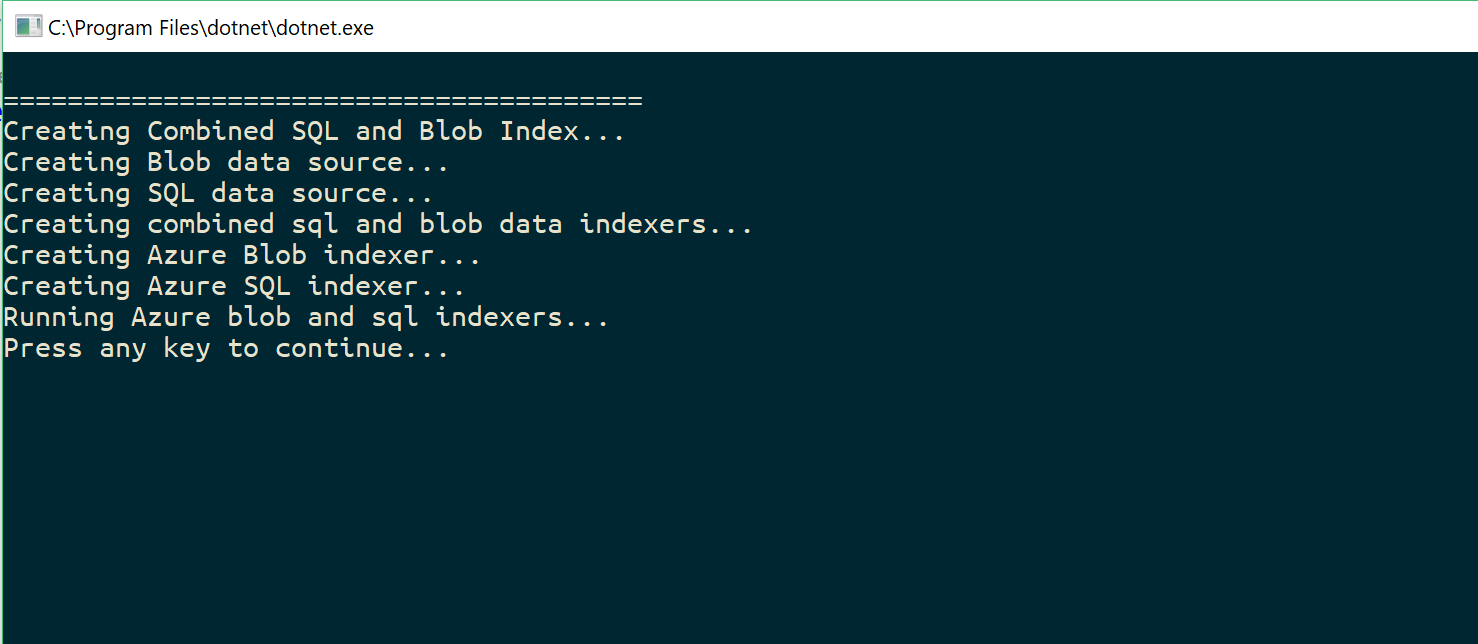
If we navigate to our Azure Search on Azure, we can see that our new combined index has been populated! Notice the highlighted documents. We are now confident that we have indexed our sources, so next we want to test this new index by running a query.
I'm using the word justice to test the search. The index looks to all scanned documents and returns the appropriate results. The following screenshots show you how the search results look like for matching Documents across both datasources.
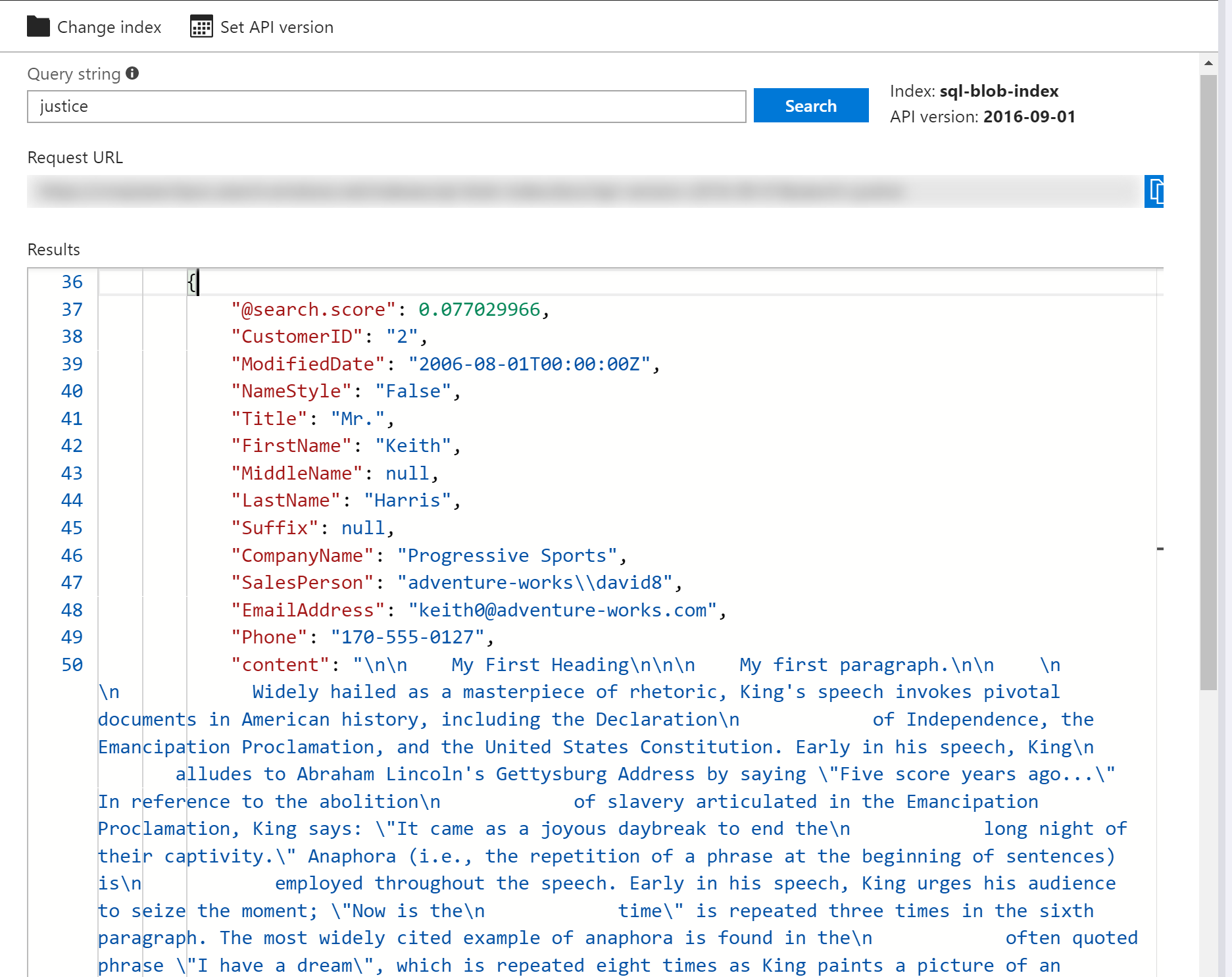
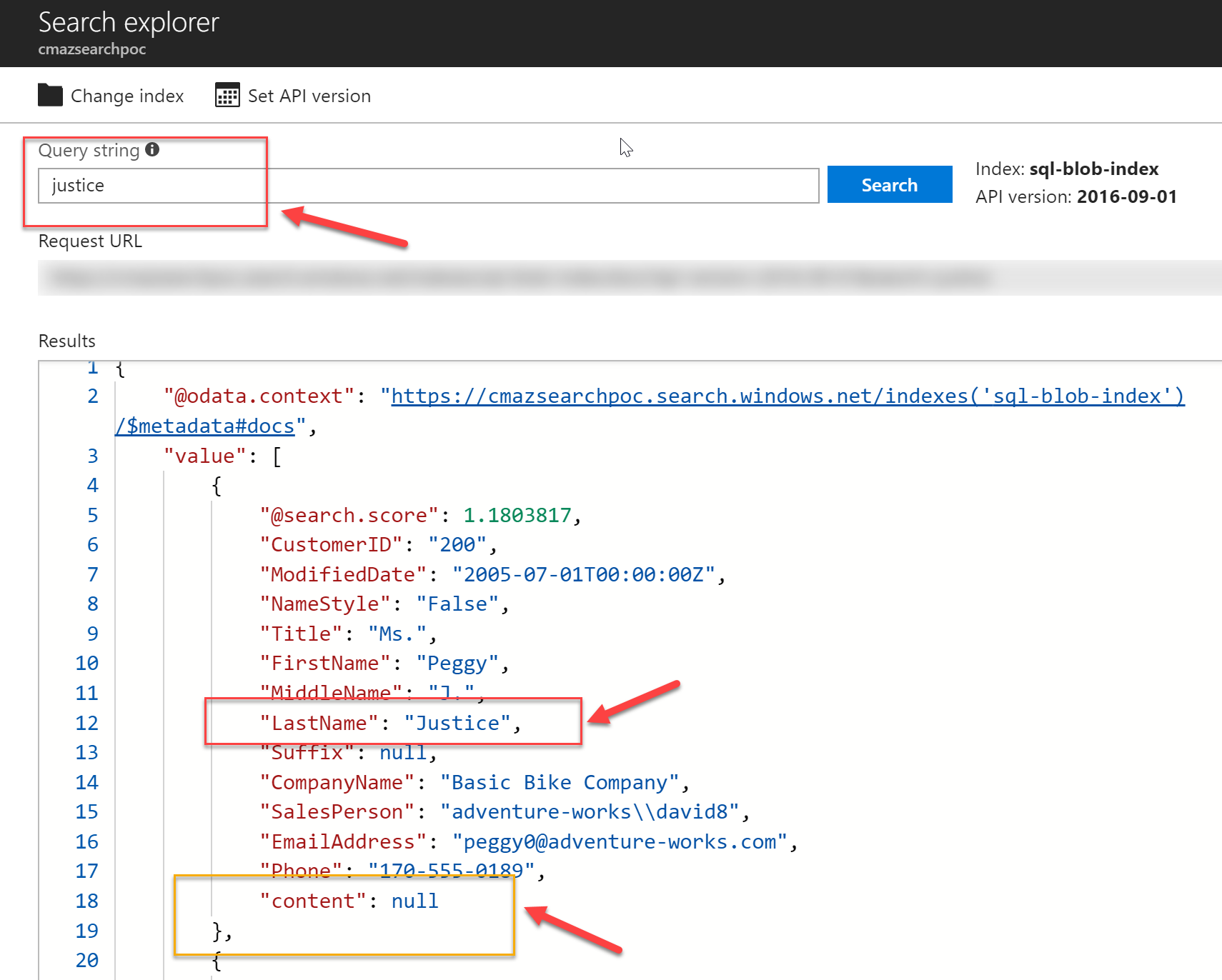
As you can see, Azure Search is extremely powerful and can be used both for basic searches and more advanced scenarios. It enables searching across multiple datasources and requires minimal configuration to set up. This post shows you how to combine multiple data sources in search and highlights some of the implementation details you need to be aware of.